まだ読み切っていないので、追記していく予定。
『達人が教えるWebパフォーマンスチューニング』概要
章立ては以下の通り。
- Chapter 1 チューニングの基礎知識
- Chapter 2 モニタリング
- Chapter 3 基礎的な負荷試験
- Chapter 4 シナリオを持った負荷試験
- Chapter 5 データベースのチューニング
- Chapter 6 リバースプロキシの利用
- Chapter 7 キャッシュの活用
- Chapter 8 押さえておきたい高速化手法
- Chapter 9 OSの基礎知識とチューニング
概要については下記のポストにまとめられている。
- 【書評】「達人が教えるWebパフォーマンスチューニング」 Webアプリケーションのパフォーマンスを出すための指針を教えてくれる本
- 「達人が教える Webパフォーマンスチューニング ~ISUCONから学ぶ高速化の実践」レビュー
2章までは基礎知識・理論で、3章からは実践的な内容になっている。 理論の部分についての補足・批判が入った読書メモを@ymotongpooさんがまとめてくれていて、こちらも参考になる。
感想の中に、全体的にクラシックな構成(サーバーにSSHしてLinuxコマンドを叩くなど)であるというものがあった。確かにそうだと思う。学校など教育機関で学んだ人は、クラシックな構成は触り慣れているので、コンテナなどモダンな環境の実践から入りたいかもしれない。
しかし、自分は正規の教育を受けたことがなかったので、いわゆるクラシックな構成を前提にポイントを絞ったシンプルな解説をしている本書の構成が良かった。
仕事でもまだオンプレサーバーを触る機会はあるし、自分の場合こういったパフォーマンスモニタリングは苦しみがら実践で覚えるしかなかったので(知識にムラも出るし作業が危険だし効率が悪い)、本書のようにハンズオン環境を用意して解説してくれる本はありがたい。コンテナにはコンテナの考え方があり、クラシックな環境とは覚えることが異なるが、コンテナ時代にもクラシックな環境で学んだ考え方は役に立つと感じている。そして、学ぶときの構成はできるだけシンプルな方が初学者にはわかりやすくてよい。
3章から著者の一人である @catatsuyさんのprivate-isuを利用して実際にパフォーマンスチューニングを手を動かしながら学ぶ。このうち、自分が参考になったと思うことをメモしていく。
Chapter 3 基礎的な負荷試験 読書メモ
改善していく順序は以下の通り。
1. ログを整備する
- Nginxの設定を変更してアクセスログを見やすい形に整形する(JSONにする)
- ログをパースするツールを入れる。alpを使っているが、LTSV形式にしてlltsvでパースするのもよさそう
- ログをローテーションする
- 定時でログをローテーションする必要はないので、随時必要なときにローテーションする。nginx reloadするか、nginx -s repoenでmasterプロセスにシグナルを送信する
2. ベンチマーカーを利用した負荷試験を実行する
- abコマンドを使う
- 最初は直列で実行する
- ベンチマーカーの結果とアクセスログを比較してだいたい同じになることを確認する
- 大きく異なる場合はNgixを実行しているサーバーとベンチマーカーを実行しているホストとの間のネットワークに問題がある可能性がある。Nginxを実行しているサーバー内でベンチマーカーを実行してみる
3. CPU利用率の高いプロセスを確認してボトルネックを探す
- topコマンドを使う
- ホスト全体で使えるCPUは何コアか?
- 過大にCPUを使っているプロセスはないか?
チューニングを行うたびに、再度負荷試験を実行して結果を確認する。また、ベンチマーカーの並列度をあげて負荷試験を再度実行する。
実践メモ
アクセスログで注目すべきはスループット
Nginxのログのうち、パフォーマンス観点から注目すべきものがいくつかある。 パフォーマンスを改善するとわかりやすく変化数値としては、レイテンシとスループットの2つがある。
- Time per requests(レスポンスタイム/レイテンシ)
- 1リクエストの処理にかかる時間
- Request per seconds(スループット)
- 1秒間に処理できたリクエスト数
ツールを使って負荷をかけベンチマークを取る際、まずレイテンシに注目するとわかりやすい。しかし、レイテンシは削減していくと利用者の体感に変化がなくなる(10ms以下の違いは利用者にはわからない)。 そこで、 実運用においてはスループットが重要な指標となる。 多数のリクエストが発生した場合に利用者の体感に影響するため。
レイテンシとスループットは反比例の関係になるが、レイテンシの短縮には限界があり、それだけではスループットは向上しない。スループットの向上のためには、レイテンシの短縮と同時に、他の処理の最適化が必要になる。
(感想: レイテンシとスループットってなぜか覚えられない。英語と日本語がつながらないので、図で覚えている。)
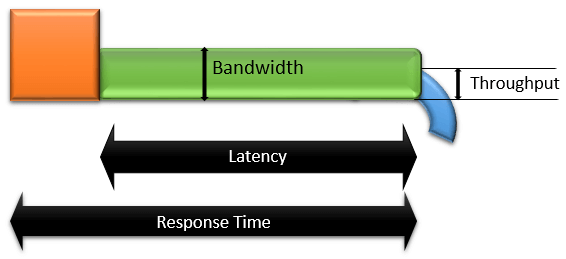
ref: Latency, Bandwidth, Throughput and Response Time
# JSON形式に変換したログをalpで整形する
$ tail -n 10 /var/log/nginx/access.log.json | alp json -o count,method,uri,min,avg,max
# シグナルを送り、ログファイルを再オープンする(ログファイルがローテーションされたことを通知する)
# ログの形式を変えたときなどに実行する
$ nginx -s reopen
topコマンドの%表示に注意
/proc/cpu を確認すると、ホスト全体で使えるCPUが何コアかわかる。EC2の場合はインスタンスタイプから逆引きできる。
%Cpu(s) からそのうちどのくらいが使用されているかわかる。2コアの場合、50%だと1コアが使われていることになる。 ここでの %表示は1コアあたりの使用率ではなく、全体の使用率に対する割合であることに注意する。
$ top
top - 09:58:51 up 23 min, 2 users, load average: 0.27, 0.
Tasks: 109 total, 1 running, 108 sleeping, 0 stopped, 0 zombie
%Cpu(s): 50.7 us, 0.8 sy, 0.0 ni, 48.3 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3843.5 total, 2597.1 free, 631.6 used, 614.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2983.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# ↓CPUがどのくらい利用されているか(2コアなので、50%が1コア)
622 mysql 20 0 1784476 419584 35872 S 98.0 10.7 2:18.19 mysqld # mysqldが異常にCPUを使用しており、ボトルネックになっていることがわかる
450 isucon 20 0 1089196 19504 8132 S 4.7 0.5 0:05.41 app # Webアプリケーションのプロセス(app)がどのくらいCPUを使っているかわかる
528 www-data 20 0 55836 5512 3600 S 0.3 0.1 0:00.03 nginx # Webサーバーのプロセス(nginx)がどのくらいCPUを使っているかわかる
...
MySQLがボトルネックだった場合の対応
まずスロークエリログを出力する。 MySQLではデフォルトでスロークエリログが出力されないので自分で設定を変更する必要がある。 また、パフォーマンスチューニングの際には、スロークエリログにすべてのクエリを出力するようにしておくことで、遅くはないが大量に発行されているクエリなど問題のあるクエリを特定できる。
mysqldumpslowコマンドなど、集計ツールを使ってスロークエリログを解析する。 mysqltunerコマンドはログ中の実行時間の合計が長いクエリから順に表示してくれる。すべてのクエリのログを出力しておくことで、一度の実行時間は短くても、大量に発行されていてリソースを消費しているクエリを発見できる。
クエリと問題になっているテーブルが特定できたら、SHOW CREATE TABLE xxx を実行してテーブルのスキーマを確認する。
EXPLAINコマンドと問題のクエリを使って、どんなクエリが発行されているのかクエリの実行計画を確認する。
インデックスが貼られていない場合は、インデックスを貼る。
チューニングしたら、スロークエリログのファイルの古い方を削除またはrenameして、チューニング後のパフォーマンス測定時のログと分離する。 MySQLではログファイルを削除したりrenameした場合、mysqladmin flush-logsを実行する必要がある。
再度負荷試験を実行する。 設定を1つ変更したら必ず負荷試験を行い、設定の効果を確認する。
(感想: この辺りのDBのチューニングをあまりやったことがないので、苦手意識があったが、意外ととっつきやすいと思った。)
ベンチマーカーの並列度を上げてCPUが有効利用されているか確認する
並列度を上げて負荷試験を実行し、変化したものと変化しなかったものを確認する。 並列度に比例して悪化したものがある場合、そこにボトルネックがある。
本書のサンプルではレスポンスタイムが悪化していた。リクエスト数に比例してレスポンスタイムが悪化しているため、単一のリクエストの時点ですでにサーバーの処理能力が飽和しており、並列にした分レスポンスタイムが長くなっていくことがわかる。
そこでdstatコマンドを利用して時系列でCPU利用率を表示し、CPUを有効に利用できているか確認する。
今回は2コアなので、idleを確認して2つのCPUコアを有効に利用できているか見る。CPUのidleが40%ほどあり、1コア分が使われていないようだとわかる。サーバーの設定を変えて複数のプロセスを並列に実行することで、CPUを有効に利用できる可能性がある。
# CPU負荷をコアごとに表示する
$ dstat --cpu
## usr … ユーザ空間で使われたCPU使用時間の割合
## sys … システム空間で使われたCPU仕様時間の割合
## idl … アイドル状態のCPU時間の割合
usr sys idl wai stl
57 14 29 0 0
62 8 30 0 0
59 12 29 0 0
58 13 29 0 0
58 12 30 0 1
このまま書いていくと長くなるので、分けることにする。