はじめに
前回は用語の確認をしました。
今回は実際に流れに沿って静的解析をやってみます。
参考
静的解析の流れ
次のようなステップです。
- ソースコードを 字句解析 して、トークンに分割する
- トークンを 構文解析 して、抽象構文木(AST)に変換する
また、構文解析では対処できない場合は、さらに意味解析や型解析を行って情報を抽出することもあります。
字句解析で使うパッケージ
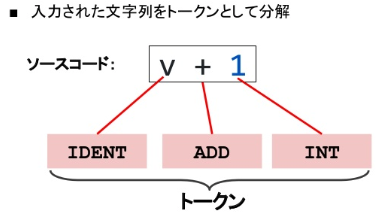
ソースコードをトークンとして分割する
scanner/ScanのExampleをもとに、ソースコードを字句解析し、トークンをつくってみます。
なお、処理を見やすくするためにエラーを潰しているところがあります。
package main
import (
"fmt"
"go/scanner"
"go/token"
)
func main() {
// 字句解析するソースコード
src := []byte("v + 1")
// スキャナーの初期化を行う
var s scanner.Scanner
// ファイルの位置や長さに関する情報を保持する構造体(token.FileSet型)を用意する ※ 補足参照
fset := token.NewFileSet()
// ファイルをつくり、必要な値を与える
file := fset.AddFile("", fset.Base(), len(src))
// ソースコードをトークンにするための処理を行う(ここでファイルを使う)※ 補足参照
s.Init(file, src, nil, scanner.ScanComments)
for {
// トークンを読み出す
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
scanner/Scanはソースコードを読み込み、トークンの位置、トークン、srcで与えた値の文字列リテラルを返します。
また、この処理をEOF(ファイルの終端)に達するまで繰り返し行います。
文字列リテラルとは、ざっくりいうと、ソースコード内に値を直接表記されている0文字以上の連続した文字列の塊のことです。
出力結果です。
1:1 IDENT "v"
1:3 + ""
1:5 INT "1"
1:6 ; "\n"
行数、行の中の位置、トークン、文字列リテラルが出力されました。
補足: token.FileSetについて
ここで、token.NewFileSet()という部分について解説します。
ソースコードの解析にファイルやファイルシステムは関係ないのではないか?と思うかもしれません。わたしも疑問に思いました。
上の処理でファイルは、ソースコードの解析の中で必要となるトークンの位置を取得する目的でつくっています。
トークンの位置は、scanner/Scanの処理部分で使っています。
scanner/Scanの戻り値は下記の3つです。
func (s *Scanner) Scan() (pos token.Pos, tok token.Token, lit string)
このうち、 posが位置に関係するものです。
トークンの位置情報は絶対的なものではなく、token.FileSetを基準にして相対的に決まります。
また、token.FileSetにおける「ファイル」というのは概念上のもので、ファイルシステム上に存在する必要はありません。
トークンの位置を図るための元になる値を与えるために、便宜的に「ファイル」をつくっているのです。
構文解析で使うパッケージ
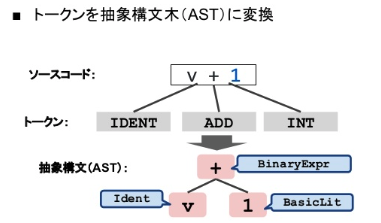
ソースコードから抽象構文木(AST)を抽出する
先ほどつくったトークンを構文解析して、抽象構文木(AST)に変換してみます…
と行きたいところですが、
じつは go/parserパッケージを使うことでソースコードを字句解析して抽象構文木(AST)へ変換するところまで一気に行うことができます。
package main
import (
"go/ast"
"go/parser"
)
func main() {
src := "v + 1"
// ソースコードを抽象構文木(AST)に変換する
expr, _ := parser.ParseExpr(src)
// 抽象構文木(AST)をフォーマットしてプリントする
ast.Print(nil, expr)
}
ast.Print は抽象構文木を人間に読みやすい形でプリントします。デバッグ時に便利な関数です。
出力結果を見てみます。
0 *ast.BinaryExpr {
1 . X: *ast.Ident {
2 . . NamePos: 1
3 . . Name: "v"
4 . . Obj: *ast.Object {
5 . . . Kind: bad
6 . . . Name: ""
7 . . }
8 . }
9 . OpPos: 3
10 . Op: +
11 . Y: *ast.BasicLit {
12 . . ValuePos: 5
13 . . Kind: INT
14 . . Value: "1"
15 . }
16 }
いきなり抽象構文木を手に入れることができました。
また、 parser/ParseFileを使うことでソースコードではなくファイルを対象にすることもできます。
func ParseFile(fset *token.FileSet, filename string, src interface{}, mode Mode) (f *ast.File, err error)
おわりに
以上で静的解析を行う際の流れを確認しました。
抽象構文木(AST)は取得できたけれども、いまはまだ何がうれしいのかよくわかりません。
そこで次回は抽象構文木(AST)を操作してトラバースしたりファイルに出力したりしてみます。